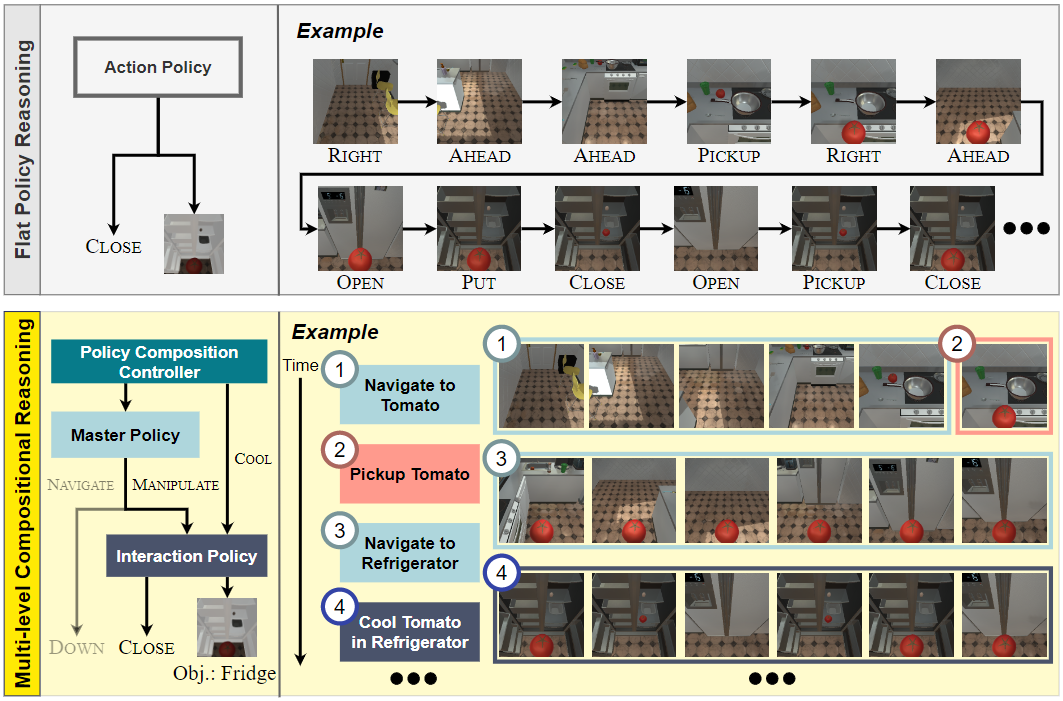
Robotic agents performing domestic chores by natural language directives are required to master the complex job of navigating environment and interacting with objects in the environments. The tasks given to the agents are often composite thus are challenging as completing them require to reason about multiple subtasks, e.g., bring a cup of coffee. To address the challenge, we propose to divide and conquer it by breaking the task into multiple subgoals and attend to them individually for better navigation and interaction. We call it Multilevel Compositional Reasoning Agent (MCR-Agent). Specifically, we learn a three-level action policy. At the highest level, we infer a sequence of human-interpretable subgoals to be executed based on language instructions by a highlevel policy composition controller. At the middle level, we discriminatively control the agent’s navigation by a master policy by alternating between a navigation policy and various independent interaction policies. Finally, at the lowest level, we infer manipulation actions with the corresponding object masks using the appropriate interaction policy. Our approach not only generates human interpretable subgoals but also achieves 2.03% absolute gain to comparable state of the arts in the efficiency metric (PLWSR in unseen set) without using rule-based planning or a semantic spatial memory.
Observing that the visual information for navigation considerably varies over time while interacting with objects is largely stationary, we argue that the agent benefits from learning different policy modules for these two different tasks as follows. The navigation needs to reason about the temporal history and global environment information. The interaction with objects requires focusing on local visual cues for precise object localization. In addition, there is a sample imbalance between navigation and interaction actions as navigation actions are far more frequent than interaction actions. This would bias a learned model towards more frequent actions, i.e., navigation.
Based on these observations, we design an architecture with three levels of compositional learning; (1) a high-level policy composition controller (PCC) that uses language instructions to generate a sequence of sub-objectives, (2) a master policy that specialises in navigation and determines when and where the agent is required to perform interaction tasks, and (3) interaction policies (IP) that are a collection of subgoal policies that specialise in precise interaction tasks.
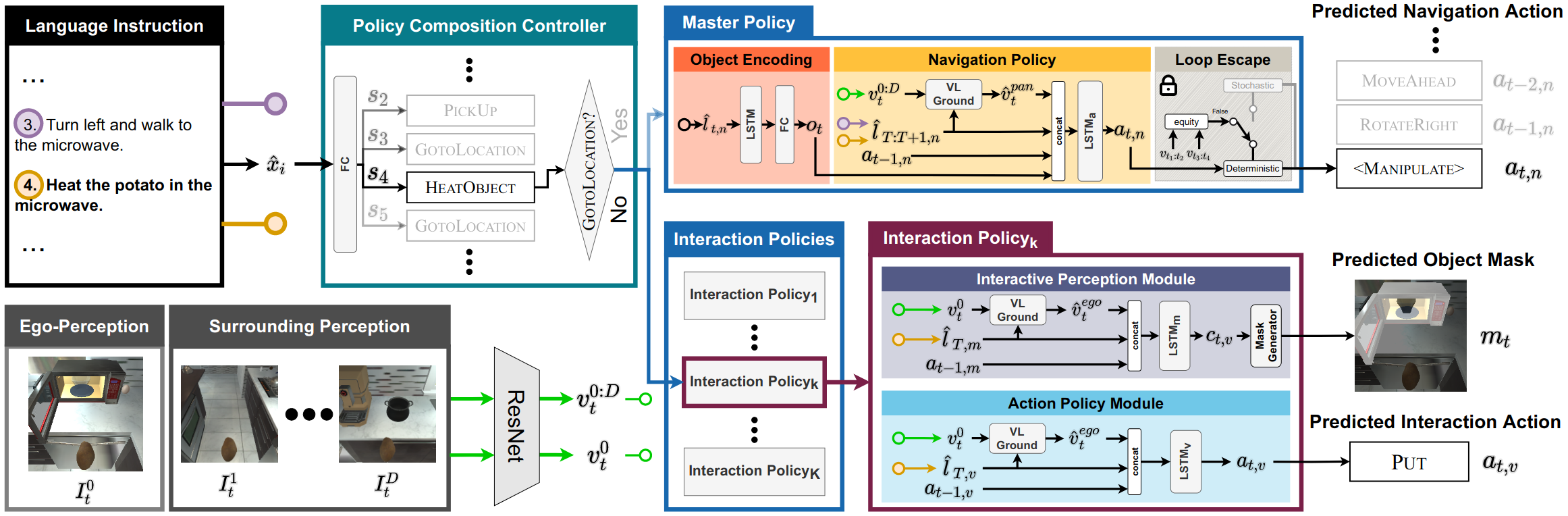
The nature of the long-horizon instruction following is highly complex. To address this, we argue that it is beneficial to first generate a high-level subgoal sequence, and then tackle each subgoal individually. For inferring the subgoals, we propose a policy composition controller (PCC) that predicts a subgoal for each ‘step-by-step’ instruction. It gives the intuition on what the agent is attempting to accomplish at any particular instance. PCC consists of a Bi-LSTM to encode language instructions and a fully-connected layer for subgoal classification. PCC achieves 98.5% accuracy on the validation set in ALFRED.
The reasoning required for navigation is significantly varied from the interaction. To this end, we propose to use a dedicated module for navigation, which we call ‘master policy.’ It not only performs navigation but simultaneously also marks the locations for object interaction along the way.
Subtask Language Encoding. The language instructions for a given task can be divided into two types; (1) navigation and (2) interaction. We observed that for completing a given compositional task, the agent needs to navigate to the necessary locations and then interact with relevant objects. For this, we propose to encode the combination of instructions for navigation. In particular, we regard the subtask instruction as a combination of (1) navigation to discover the relevant object and (2) corresponding interactions. We encode these language instruction combinations in a similar manner as PCC.
Object Encoding Module (OEM). To find the correct object to be interacted with, we propose an object encoding module that takes as input the subtask language instruction and gives the target object that the agent must locate for interaction. This guides the agent’s navigation by acting as a navigation subgoal monitor that indicates the end of the navigation subgoal and shifts control to the next interaction policy. During navigation, the subgoal monitor uses a pretrained object detector that validates if the relevant object is present in the current view or not. If the agent spots the item, it switches to the appropriate interaction policy; otherwise, it continues to navigate.
Navigation Policy. The second component of the master policy is the navigation policy that generates the sequence of navigable low-level actions to locate the correct object for interaction using the processed multi-modal data as input. It uses visual features, subtask instruction features, object encoding, and the embedding of the preceding time step action as inputs. To capture the relationship between the visual observation and language instructions, we dynamically generate filters based on the attended language features and convolve visual features with the filters.
Following MOCA, we exploit separate streams for action prediction and object localization due to the contrasting nature of the two tasks. Each interaction policy consists of an action policy module which is responsible for predicting the sequence of actions corresponding to the interaction subgoal, and an interaction perception module which generates the pixel-level object mask for objects that the agent needs to interact with at a particular time step.
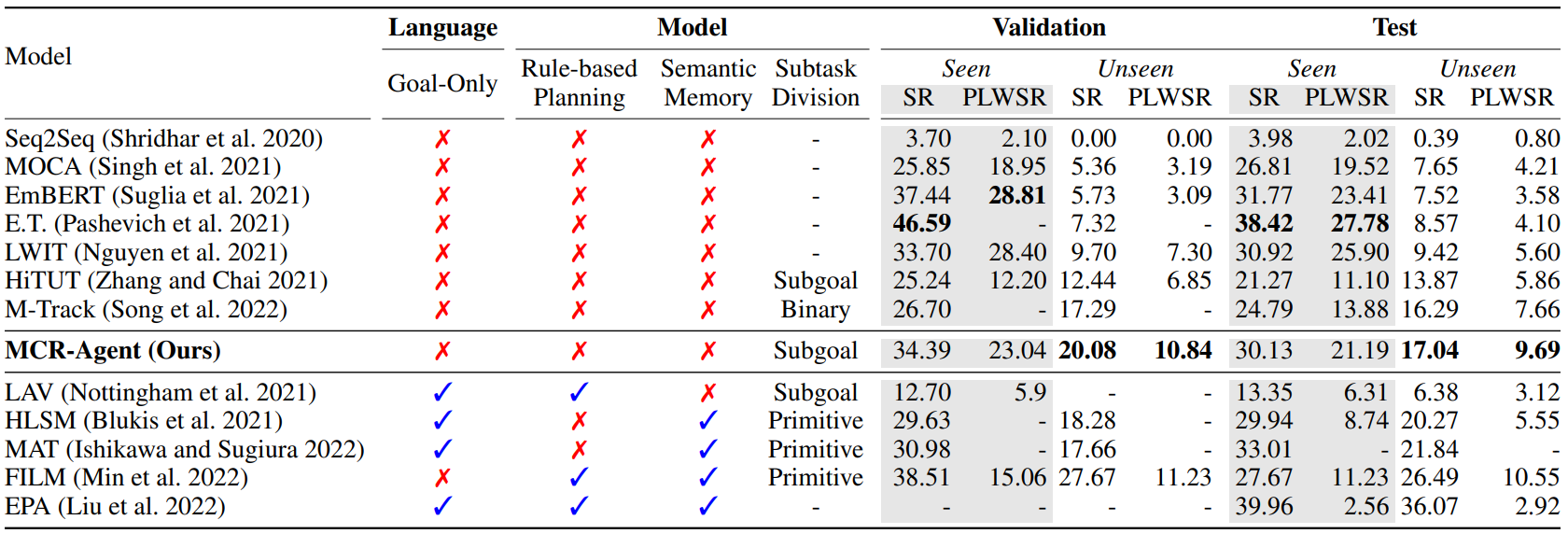
We employ ALFRED to evaluate our method. There are three splits of environments in ALFRED: ‘train’, ‘validation’, and ‘test’. The validation and test environments are further divided into two folds, seen and unseen, to assess the generalization capacity. The primary metric is the success rate, denoted by ‘SR,’ which measures the percentage of completed tasks. Another metric is the goal-condition success rate, denoted by ‘GC,’ which measures the percentage of satisfied goal conditions. Finally, path-length-weighted (PLW) scores penalize SR and GC by the length of the actions that the agent takes.
In unseen environments, MCR-Agent outperforms most prior-arts in terms of PLWSR for both test and validation folds. For seen environments in the test fold, MCR-Agent shows comparable performance with LWIT and EmBERT in terms of SR and PLWSR but these works exhibit relatively stronger bias towards seen environments, which is evidenced by the significant drop in their unseen SR (i.e., 69.5% and 76.3% relative drop, respectively). Similarly, E.T. decently performs in seen environments but shows a drastic drop (77.7% relative) of SR in unseen environments.
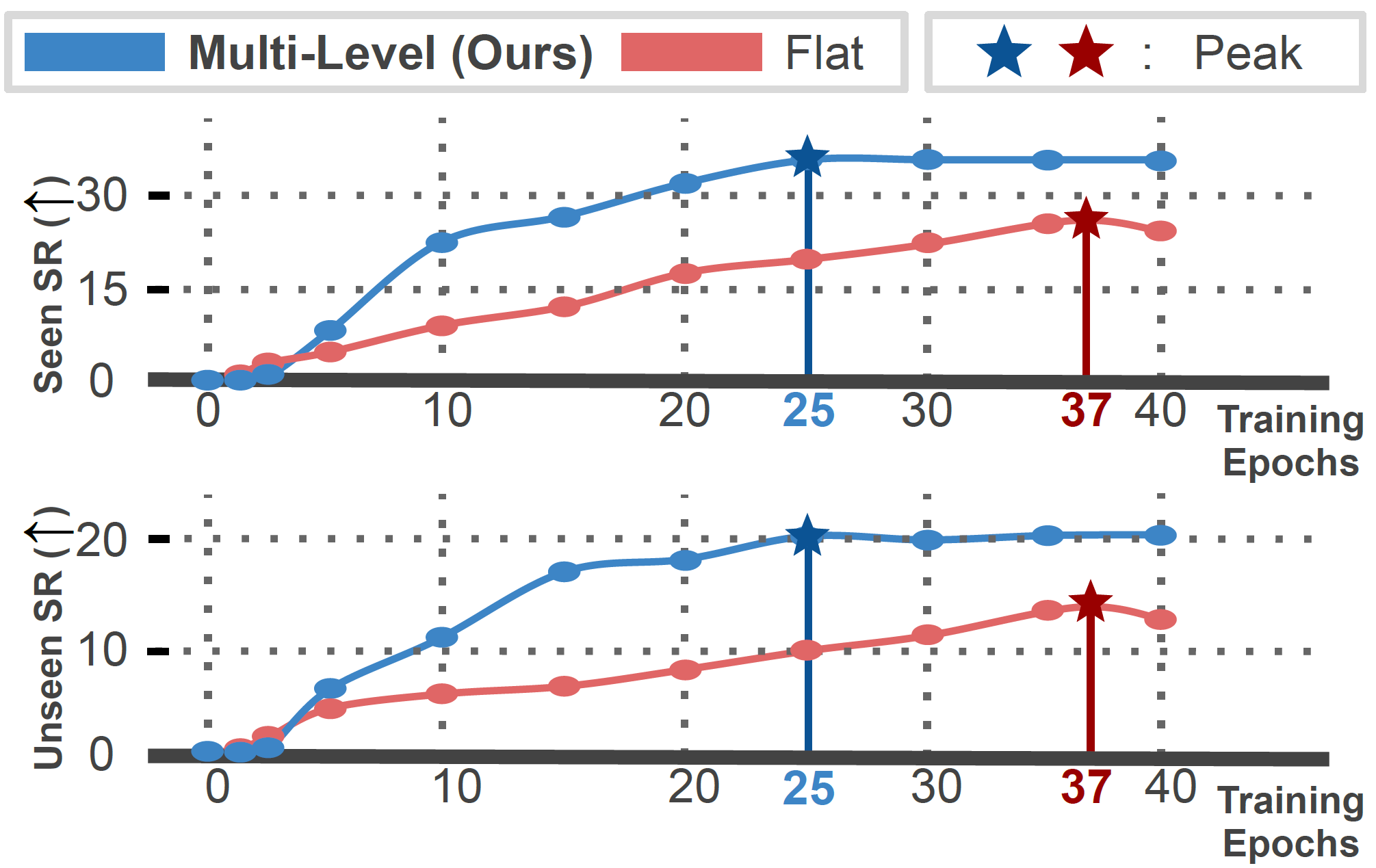
Our multi-level hierarchical agent converges significantly faster than the flat agent (25th vs. 37th epoch), demonstrating the computational efficiency of our approach. Our policies are trained in two stages. We train interaction policies first, which collectively takes two epochs to converge. We include them in computation and begin the hierarchical agent’s curve from the 3rd epoch, which is effectively the 1st epoch for the master policy.
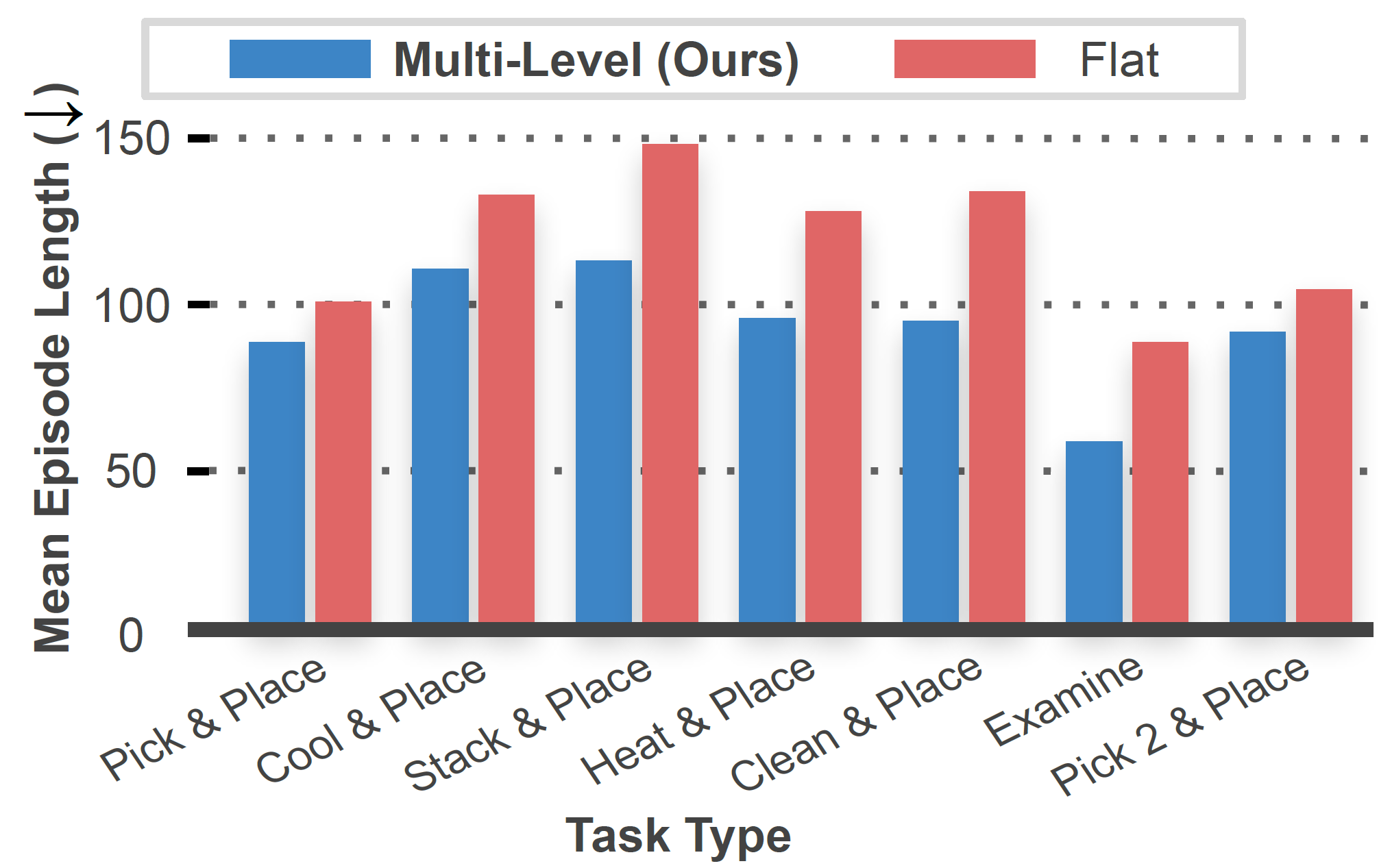
The hierarchical agent consists of the master policy that is dedicated solely to navigation, giving it a significant advantage over the flat agent that learns everything using the same network parameters. It was observed that due to the wide action space, the flat agent occasionally executes irrelevant interactions along the trajectory, which is not the case with MCR-Agent. The dedicated action sets for the master policy and interaction policies improve MCR-Agent by allowing the agent to avoid any unnecessary interactions while traversing to discover the desired object. The interaction policies also perform significantly better because they only master certain short-horizon tasks, which speeds up and simplifies the learning process.
For more details, please check out the paper.
@inproceedings{bhambri2023multi,
author = {Bhambri, Suvaansh and Kim, Byeonghwi and Choi, Jonghyun},
title = {Multi-Level Compositional Reasoning for Interactive Instruction Following},
booktitle = {AAAI},
year = {2023},
}