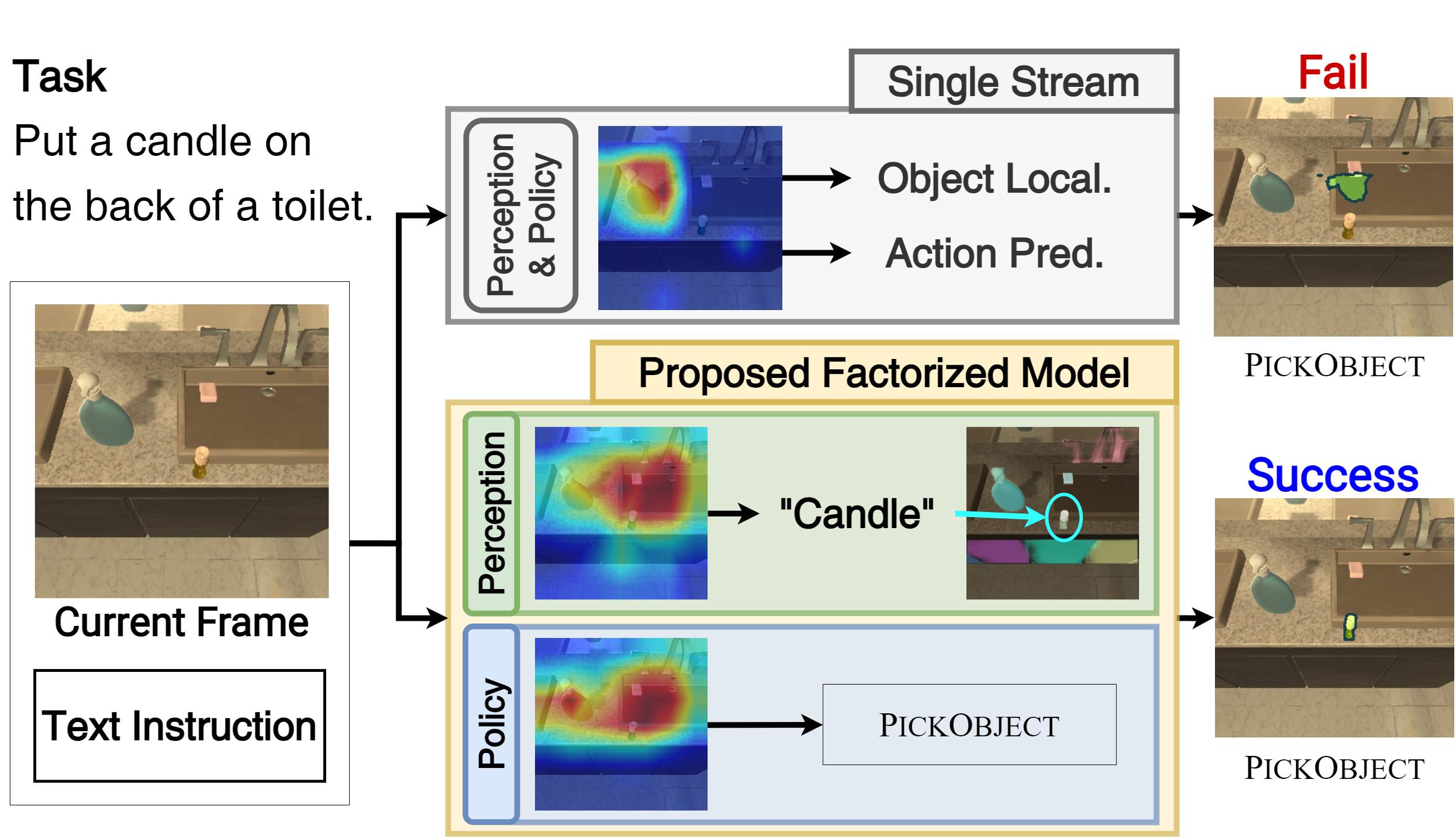
Performing simple household tasks based on language directives is very natural to humans, yet it remains an open challenge for AI agents. The ‘interactive instruction following’ task attempts to make progress towards building agents that jointly navigate, interact, and reason in the environment at every step. To address the multifaceted problem, we propose a model that factorizes the task into interactive perception and action policy streams with enhanced components and name it as MOCA, a Modular Object-Centric Approach. We empirically validate that MOCA outperforms prior arts by significant margins on the ALFRED benchmark with improved generalization.
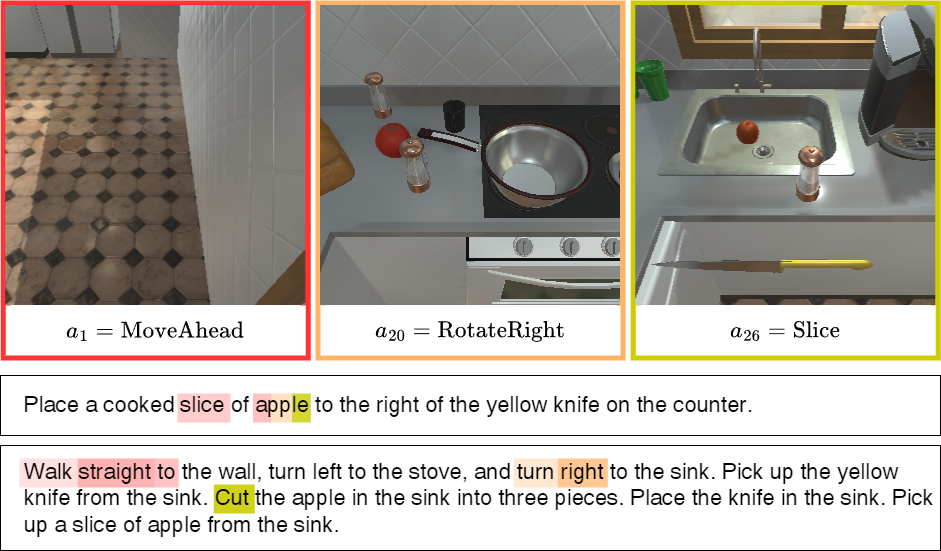
An interactive instruction following agent performs a sequence of navigational steps and object interactions based on egocentric visual observations it receives from environment. These actions and interactions are based on natural language instructions that the agent must follow to accomplish the task. We approach this by factorizing the model into two streams, i.e. interactive perception and action policy, and train the entire architecture end-to-end.
Action prediction requires global scene-level understanding of the visual observation to abstract it to an action. On the other hand, for object interaction, the agent needs to focus on both scene-level and object-specific features to achieve precise localisation. Given the contrasting nature of the two tasks, MOCA has separate streams for action prediction with Action Policy Module (APM) and object localisation with Interactive Perception Module (IPM).
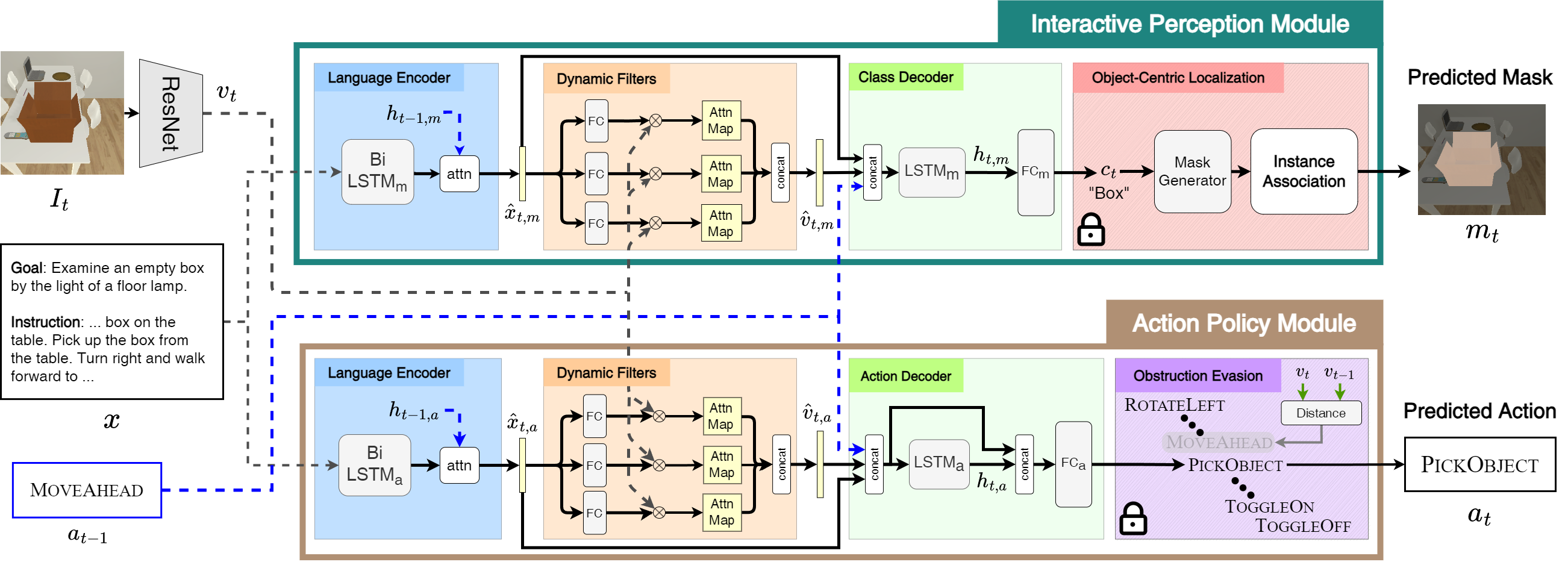
Visual grounding helps the agent to exploit the relationships between language and visual features. This reduces the agent’s dependence on any particular modality while encountering unseen scenarios. It is a common practice to concatenate flattened visual and language features. However, it might not perfectly capture the relationship between visual and textual embeddings, leading to poor performance of interactive instruction following agents. Dynamic filters are conditioned on language features making them more adaptive towards varying inputs. This is in contrast with traditional convolutions which have fixed weights after training and fail to adapt to diverse instructions. Hence, we propose to use dynamic filters for the interactive instruction following task. Particularly, we use a filter generator network comprising of fully connected layers to generate dynamic filters which attempt to capture various aspects of the language from the attended language features.
We bifurcate mask prediction into target class prediction and instance association. This bifurcation enables us to leverage the quality of pre-trained segmentation models while also ensuring accurate localisation.
Target Class Prediction. MOCA first predicts the target object class that it intends to interact with at the current time step. The predicted class is then used to acquire the set of instance masks corresponding to the predicted class from the mask generator.
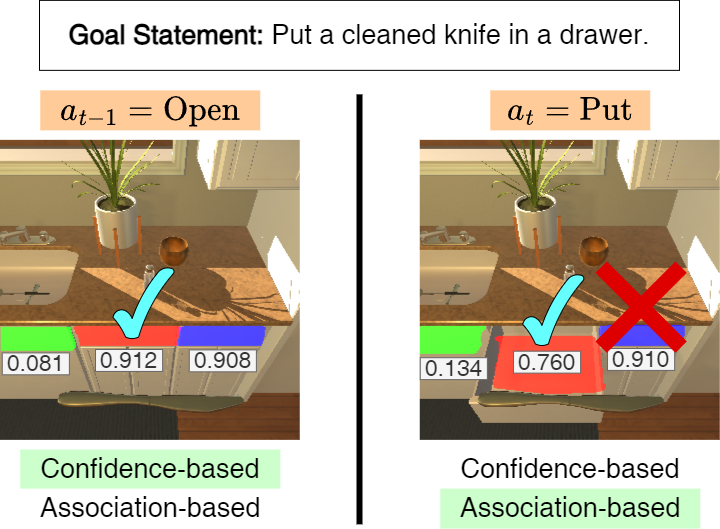
Instance Association. A straightforward solution to choose one of the correct mask instances from a pre-trained mask generator is to pick the highest confidence instance. However, when it interacts with the same object over an interval, it is more important to remember the object the agent has interacted with, since its appearance might vary drastically during multiple interactions. To address all the scenarios, we propose a two-way criterion to select the best instance mask. The confidence based criterion chooses the mask with the highest confidence score. On the contrary, the association based criterion chooses the mask whose center is closest to the one that the agent has interacted before.
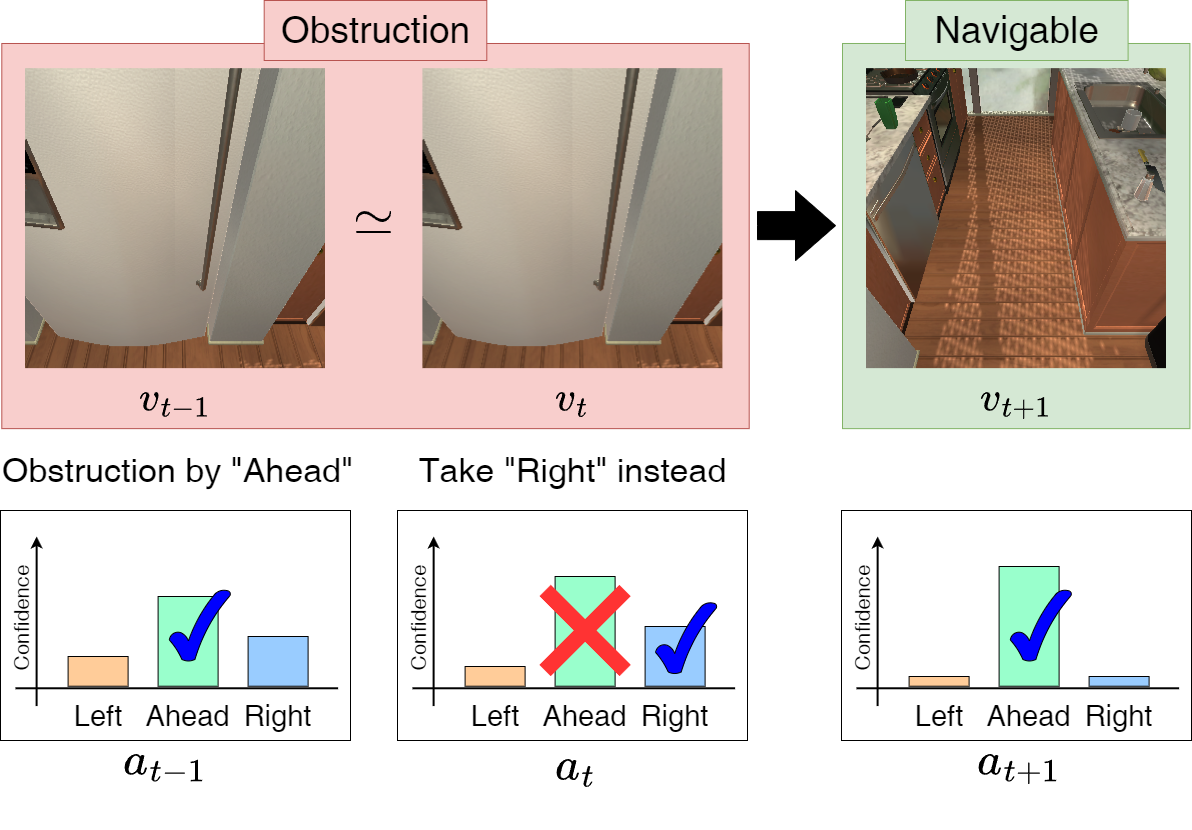
The agent learns to not encounter any obstacles during training based on the expert ground truth actions. However, during inference, there are various situations when the agent gets stranded around immovable objects. To address such unanticipated situations, we propose an ‘obstruction evasion’ mechanism in the APM to avoid obstacles at inference time. While navigating in the environment, at every time step, the agent computes the distance between visual features at the current time step and the previous time step with a tolerance hyper-parameter. If the distance is within the tolerence, we regard the current state as obstruction. To evade the obstruction, we remove the action that causes the obstruction from the action space and instead take the second-best action (i.e., the action with the second-highest confidence score).
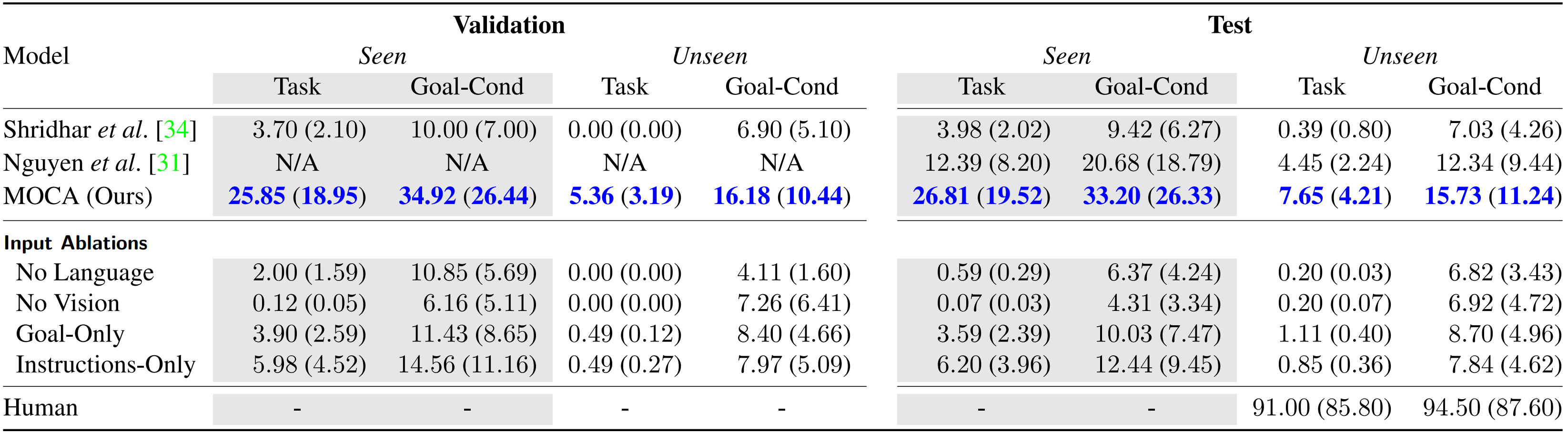
We employ ALFRED to evaluate our method. There are three splits of environments in ALFRED: ‘train’, ‘validation’, and ‘test’. The validation and test environments are further divided into two folds, seen and unseen, to assess the generalization capacity. The primary metric is the success rate, denoted by ‘SR,’ which measures the percentage of completed tasks. Another metric is the goal-condition success rate, denoted by ‘GC,’ which measures the percentage of satisfied goal conditions. Finally, path-length-weighted (PLW) scores penalize SR and GC by the length of the actions that the agent takes.
As shown in the figure, MOCA shows significant improvement over the prior arts on all metrics. The higher success rate in the unseen scenes indicates its ability to generalize in novel environments. We achieve an improvement of 14.42% and 3.20% in Seen and Unseen Task SR over Nguyen et al. that won ALFRED challenge in ECCV 2020.
For more details, please check out the paper.




@inproceedings{singh2021factorizing,
author = {Singh, Kunal Pratap and Bhambri, Suvaansh and Kim, Byeonghwi and Mottaghi, Roozbeh and Choi, Jonghyun},
title = {Factorizing Perception and Policy for Interactive Instruction Following},
booktitle = {ICCV},
year = {2021},
}